In this post, we will understand how a CPU executes instructions on a high level by illustrating the instruction cycle using a step-by-step example. We also cover interrupts and how they affect the instruction cycle.
A CPU executes instructions using a cycle of steps known as the instruction cycle.
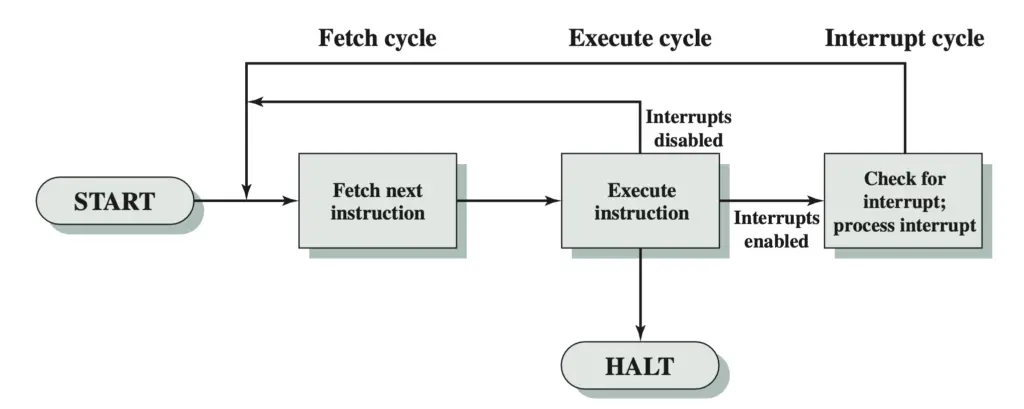
The instruction cycle consists of three steps to fetch, decode, and execute instructions. It is, therefore, also known as the fetch-decode-execute cycle.
Sometimes the cycle is described as consisting only of the fetch and the execute operation.
This cycle is repeated continuously as long as the computer is running. If it stops, the computer has either been turned off, or it has crashed.
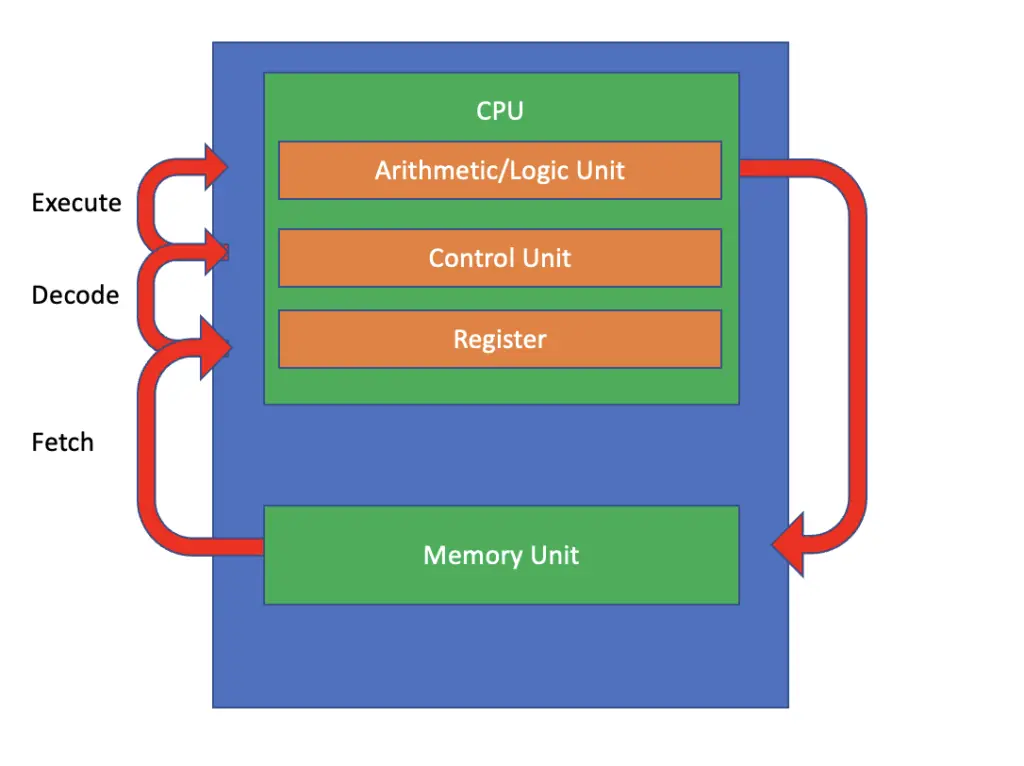
In the blog post on the von Neumann Architecture, we established that the CPU consists of a control unit for processing the instructions sent to the CPU, the arithmetic logic unit for performing the operations specified in the instructions, and registers for storing instructions and data that are immediately required by the CPU.
The fetch-decode-execute cycle makes use of these components in addition to the memory unit.
In the fetch step of the cycle, the instructions are retrieved from the memory unit (RAM) and stored in the registers on the CPU. Next, the control unit decodes the instructions, which are then executed by the arithmetic and logic unit. The results of the instruction execution are sent back to RAM for storage, and the next instruction cycle begins.
The number of instruction cycles a CPU can execute is stated as clock speed and measured in Hertz. If a CPU has a clock speed of 2 700 000 000 Hertz or 2.7 GHz, it executes 2.7 billion instruction cycles per second.
In the following section, we will walk through the operations performed during the instruction cycle. Recall that a CPU has several different registers
For an explanation of what these registers do, check out my post on von Neumann architecture.
The instruction cycle begins with the fetch operation. The program counter keeps track of the next instruction to be processed. A fetch operation starts by loading the memory address of the next instruction into the program counter. In the next step, the processor transfers the address from the program counter to the memory address register and subsequently loads the data stored at that memory location into the memory data register. The program counter is automatically incremented to the next memory location unless the current instruction explicitly points to a different memory location for the next instruction.
Let’s see how that works in practice using a concrete example:
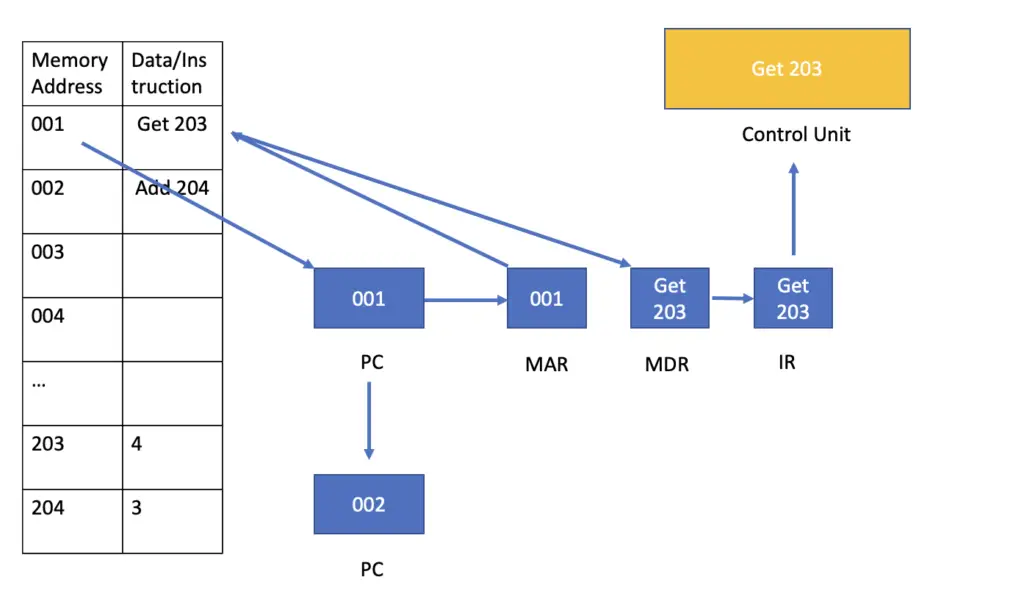
After the fetch operation, the instruction cycle continues with the decode and execute portions. During the fetch stage, the control unit has been supplied with the instruction. It now needs to decode the instruction so that the processor can understand what to do next. In our example, I’ve supplied the instruction in plain English, such as “Get 203” which tells the processor to get the piece of data stored at memory location 203. In memory, the instruction is supplied in binary. For example, in a 16-bit memory, the first 4 bits may encode the operation to be performed, while the remaining bits specify the address from which to load the data.
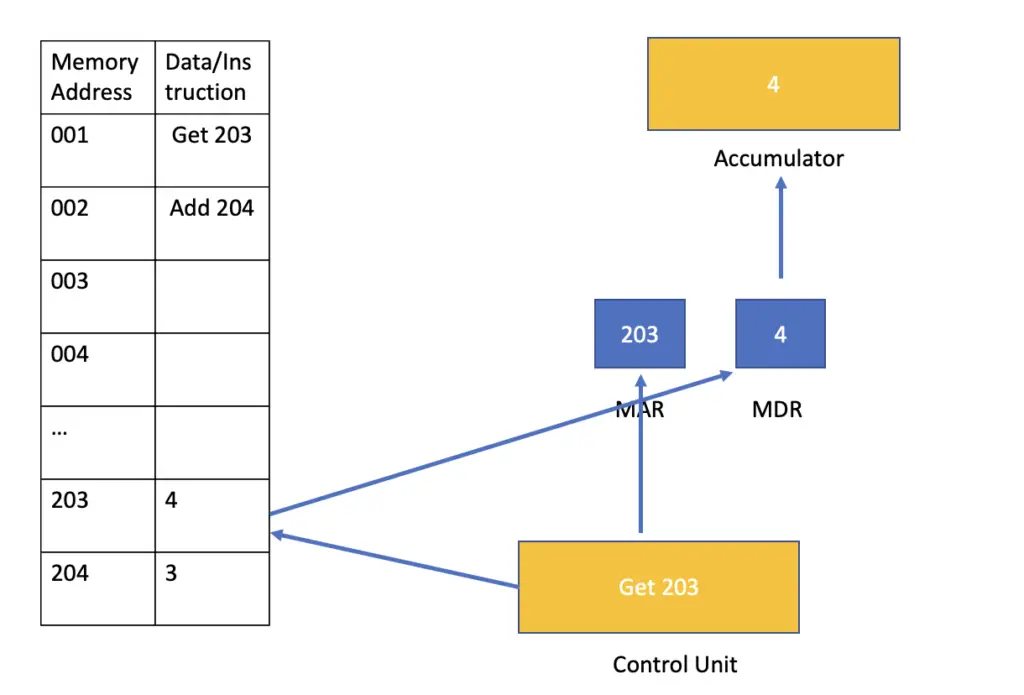
Lastly, the processor will execute the instruction supplied. So if the instruction is to get some other piece of data, the “execute” action will consist of retrieving the data from the supplied memory address and storing it in the appropriate register. If the instruction specifies a calculation such as adding two numbers, the execution of the calculation will be handed off to the arithmetic and logic unit (ALU)
Let’s continue with our concrete example:
This concludes the first fetch-decode-execute cycle. The processor starts the next cycle by fetching the next instruction stored in the program counter.
The fetching process is the same as in the previous cycle. This time, the instructions tell the processor to add the number stored at memory location 204 to the number currently stored in the accumulator.
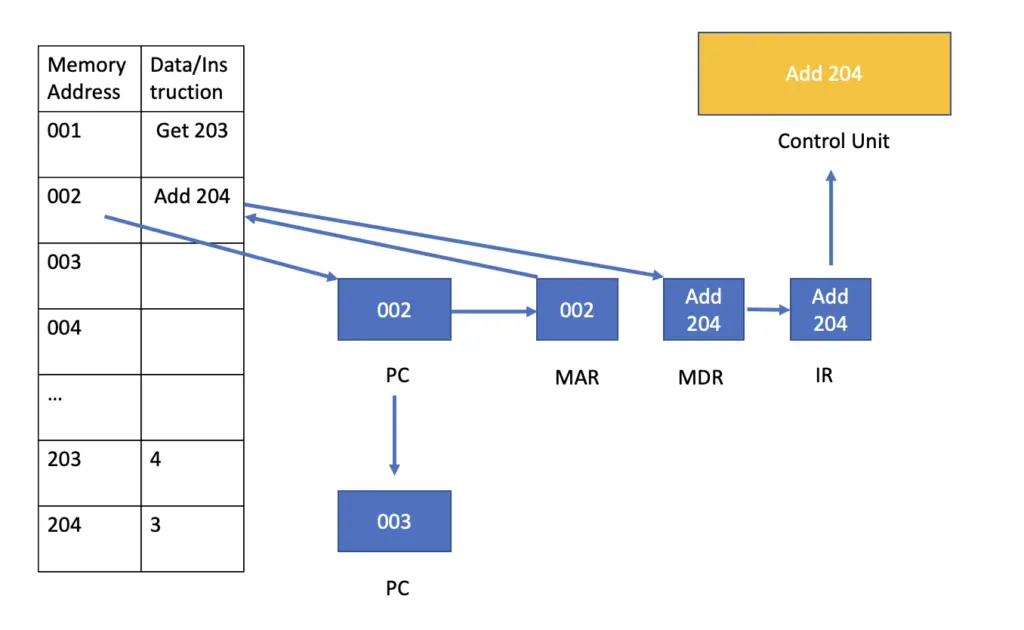
After fetching the instruction, the processor retrieves the number stored at memory address 204 and places it in the accumulator while the previously stored number is forwarded to the arithmetic and logic unit (ALU).
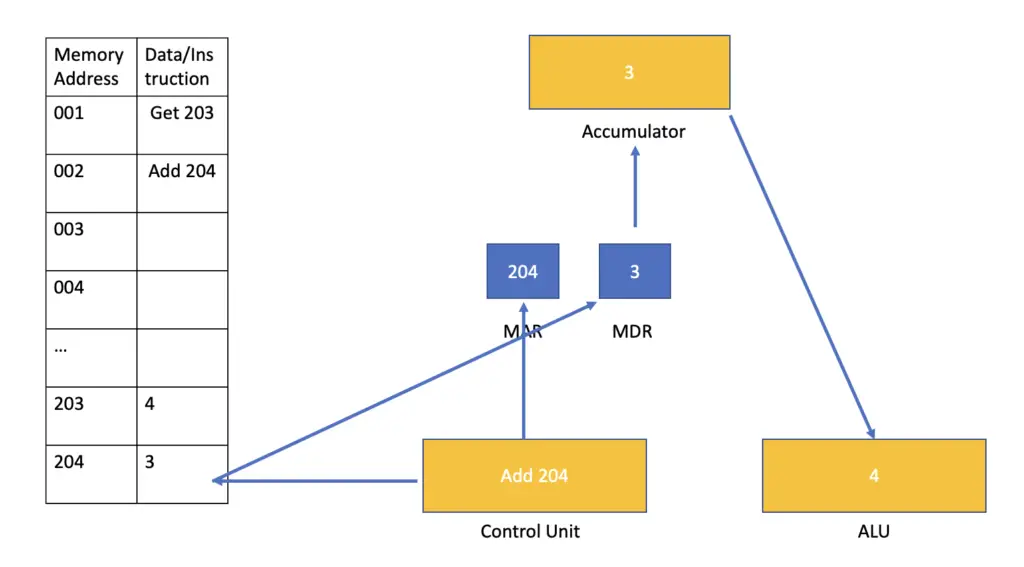
Then, the number 3 is also forwarded to the arithmetic and logic unit, where the addition specified in the instruction is performed. Finally, the result is returned to the accumulator, where it will sit until the next instruction is executed.
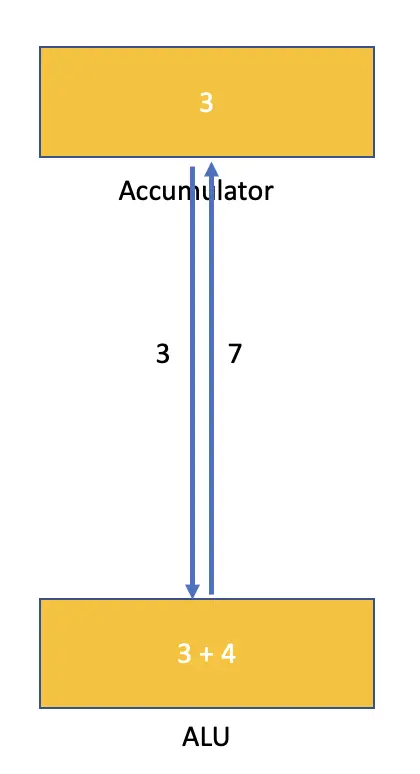
In this example, we’ve used two instruction cycles to perform the addition. But modern processors may also load several pieces of data and perform calculations in one cycle.
As the term implies, an interrupt is a mechanism by which the normal course of actions of the processor is interrupted. This may be necessary for a variety of reasons, such as hardware failure or waiting for an I/O operation to complete.
Interrupts are part of a broader class of events known as exceptions. Exceptions essentially handle cases when the CPU encounters conditions that interfere with normal processing.
The main utility of interrupts lies in their ability to improve efficiency. Performing I/O operations is usually orders of magnitude slower than normal processing. If the computer had to communicate with an external device attached via USB, such as a flash drive, without the use of interrupts, the processor would have to wait until the i/O operation completes. The processor would spend thousands of instruction cycles just polling the peripheral device, asking if it was done processing without doing any useful work.
To make processing more efficient, the processor can receive an interrupt signal from the I/O device enabling it to work on something that is unrelated to the I/O operation while that operation is in progress.
Once the I/O device is done with its operations and requires communication with the processor, it sends an interrupt request signal to the processor. The processor then interrupts the execution of its current program and services the I/O device. This is achieved via a special device known as the interrupt handler. When the processor is finished with the I/O processing, it returns to the original process.
Once an Interrupt signal arrives, the processor has to perform a series of steps to handle the interrupt and continue processing:
To include the handling of interrupts into the instruction cycle, an additional interrupt cycle is included.
If multiple interrupts occur, there are essentially two options.
If an interrupt is currently being handled and a second interrupt occurs, the processor can push the second and all subsequent interrupts onto a stack and execute them in reverse sequential order. This has the disadvantage that we cannot prioritize interrupts. If an I/O device that causes a notoriously long interrupt, like a printer, is currently executing, all other interrupts would have to wait.
Alternatively, interrupts can be associated with priorities. If an interrupt with a higher priority were to occur while a lower priority interrupt is being handled, the lower priority interrupt would itself be interrupted. The processor then would handle the higher-priority interrupt first before turning back to the lower-priority one. Naturally, the second approach engenders more complexity but is usually more efficient.
So far, we have focused on interrupts as caused by I/O devices. In fact, there are several reasons for a processor to interrupt its course of action leading to different types of interrupt handlers.
A computer relies on electricity. If there is a power outage or something overheats, the processor needs to be able to handle that case when the underlying hardware fails. The hardware failure handler also kicks in when there is an inconsistency in memory access. For example, if a piece of data is different in memory when it is accessed from when it was stored, it may cause system crashes.
Interrupts may be generated by the processor on a regular basis to perform updates or other functions that may be necessary.
If an error occurs during the execution of a program, the program itself can trigger an interrupt. If you are a programmer, you probably have run into buffer overflow errors or other errors generated when executing your program. These errors are triggered when your program attempts to do something that the processor cannot or will not handle. In that case, the processor will generate an interrupt or an exception. In fact, good programmers anticipate potential modes of failure and handle these through exceptions in their code.
The controller of an I/O device can trigger interrupts as described previously. They either start a new interrupt by requesting service from the processor, signal normal completion of an I/O process, or indicate an error condition.